
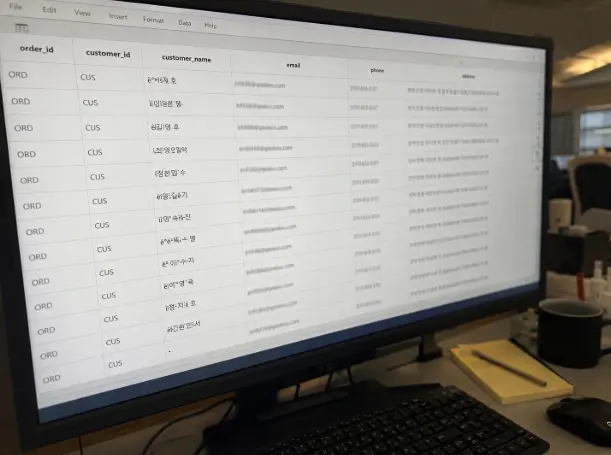
CSV 인코딩 오류로 한글 고객명이 깨진 실제 복구 기록입니다. UTF-8, EUC-KR, BOM 차이를 확인하며 7개 파일, 18,420행 중 깨진 고객명 1,136개를 2일 동안 복구한 과정을 정리했습니다.
엑셀로 CSV를 열었을 뿐인데 고객명이 전부 깨져 보였다
2026년 1월 14일 오전, 첫 번째 실수는 더블클릭이었다
문제가 시작된 시간은 2026년 1월 14일 오전 10시 20분이었다. 고객 데이터 정리 작업을 하려고 CSV 파일을 받았고, 평소처럼 아무 생각 없이 파일을 더블클릭해서 Excel 2021로 열었다.
처음에는 단순히 열람만 하려던 파일이었다. 그런데 고객명 칸에 있어야 할 한글 이름들이 “김민수”, “박지옔 같은 이상한 문자로 보였다.
총 CSV 파일 수는 7개였고, 전체 데이터 행 수는 18,420행이었다. 그중 한글이 깨진 고객명 수는 1,136개로 확인됐다.
처음에는 파일이 손상된 줄 알았다
처음 판단은 완전히 틀렸다. 나는 CSV 파일 자체가 손상됐거나, 전달 과정에서 파일이 깨졌다고 생각했다.
그래서 원본 파일을 다시 요청했고, 압축 파일로 다시 받아보기도 했다. 하지만 같은 파일을 다시 열어도 결과는 같았다.
더 큰 문제는 내가 깨진 상태로 저장을 눌렀다는 점이었다. 7개 파일 중 3개는 잘못 저장된 파일이 되었고, 이때부터 단순 확인 작업이 복구 작업으로 바뀌었다.
문제는 데이터가 아니라 인코딩 해석 방식이었다
UTF-8, EUC-KR, BOM 차이를 뒤늦게 확인했다
원인은 데이터 손상이 아니었다. UTF-8로 만들어진 CSV 파일을 엑셀이 EUC-KR처럼 해석하면서 한글 고객명이 깨져 보인 문제였다.
당시 나는 CSV를 엑셀 파일과 거의 비슷하게 생각했다. 하지만 CSV는 셀 서식이 저장된 엑셀 파일이 아니라, 쉼표로 구분된 텍스트 파일에 가까웠다.
UTF-8, EUC-KR, BOM 차이를 제대로 확인하지 않고 연 것이 가장 큰 실수였다. 특히 BOM이 없는 UTF-8 CSV는 엑셀에서 자동 인식이 꼬일 수 있다는 점을 그때 처음 체감했다.
같은 파일도 도구마다 다르게 열렸다
복구 과정에서 가장 혼란스러웠던 부분은 같은 CSV 파일인데도 도구마다 다르게 보였다는 점이다. Excel 2021에서는 깨져 보였지만, Google Sheets에서는 일부 파일이 정상적으로 열렸다.
VS Code에서는 파일 오른쪽 아래 인코딩 표시를 보고 UTF-8 여부를 확인할 수 있었다. Notepad++에서는 인코딩 메뉴에서 UTF-8, ANSI, UTF-8-BOM 상태를 비교하기 좋았다.
| 도구 | 열었던 방식 | 결과 | 느낀 점 |
|---|---|---|---|
| Excel 2021 | CSV 더블클릭 | 한글 고객명 깨짐 | 가장 빠르지만 가장 위험했다 |
| Excel 2021 | 데이터 가져오기 | 인코딩 선택 후 정상 표시 | CSV는 이 방식으로 열어야 했다 |
| Google Sheets | 파일 업로드 | 일부 파일 정상 표시 | 원본 확인용으로 유용했다 |
| VS Code | 텍스트 파일로 열기 | UTF-8 여부 확인 가능 | 인코딩 확인에 가장 편했다 |
| Notepad++ | 인코딩 메뉴 확인 | UTF-8, ANSI 비교 가능 | 깨짐 원인 추적에 도움 됐다 |
| Python 3.11 | 스크립트로 재저장 | 일부 파일 일괄 변환 | 반복 작업을 줄일 수 있었다 |
내가 실제로 사용한 복구 도구들
Excel에서는 데이터 가져오기로 다시 열었다
복구 첫 단계는 Excel 2021에서 더블클릭으로 열지 않는 것이었다. 새 통합 문서를 열고, 데이터 탭에서 텍스트 또는 CSV 가져오기를 선택했다.
그다음 파일 원본을 UTF-8로 지정하고 미리보기에서 고객명이 정상적으로 보이는지 확인했다. 이 과정을 거치니 같은 파일인데도 깨진 이름이 정상적인 한글로 표시됐다.
이때부터는 “파일을 여는 방식도 데이터 관리의 일부”라고 생각하게 됐다. 예전에는 CSV가 열리면 된다고 생각했지만, 이제는 어떻게 열렸는지가 더 중요했다.
VS Code와 Notepad++에서 인코딩을 비교했다
VS Code에서는 CSV 파일을 열고 오른쪽 아래의 인코딩 표시를 확인했다. UTF-8로 보이는 파일도 있었고, 일부는 이미 잘못 저장되어 문자 자체가 변형된 상태였다.
Notepad++에서는 같은 파일을 UTF-8, ANSI, UTF-8-BOM 기준으로 바꿔가며 표시 상태를 비교했다. 여기서 원본이 살아 있는 파일과 이미 저장 과정에서 손상된 파일을 나눌 수 있었다.
이 구분이 중요했다. 원본 데이터가 살아 있는 파일은 인코딩을 바르게 지정하면 복구가 쉬웠지만, 깨진 상태로 다시 저장된 파일은 고객명 일부를 대조해야 했다.
Python으로 일부 파일을 재저장했다
반복 작업은 Python 3.11로 처리했다. 모든 파일을 수작업으로 열고 저장하면 또 실수할 가능성이 있었기 때문이다.
특히 정상적으로 읽히는 UTF-8 CSV를 UTF-8-SIG 형식으로 다시 저장해 Excel에서 열었을 때 한글이 안정적으로 보이게 만들었다.
깨진 예시:
customer_id,name,phone
10021,김민수,010-0000-1111
10022,박지ì˜,010-0000-2222
복구 후 예시:
customer_id,name,phone
10021,김민수,010-0000-1111
10022,박지영,010-0000-2222
물론 Python으로 모든 것이 해결되지는 않았다. 이미 잘못 저장된 파일 3개는 원본 파일, 백업 파일, Google Sheets 표시 결과를 함께 비교해야 했다.
복구 전후 데이터 상태 비교
깨진 이름 수와 복구 성공률을 확인했다
전체 복구 기간은 2일이었다. 문제 발생일은 2026년 1월 14일 오전 10시 20분이었고, 복구 완료일은 2026년 1월 15일 오후 5시 40분이었다.
처음에는 단순히 한글이 보이게 만드는 것이 목표였다. 하지만 중간부터는 고객명, 고객번호, 연락처가 서로 맞는지 검증하는 작업까지 포함됐다.
| 구분 | 복구 전 | 복구 후 | 비고 |
|---|---|---|---|
| CSV 파일 수 | 7개 | 7개 | 전체 파일 확인 |
| 전체 데이터 행 수 | 18,420행 | 18,420행 | 행 누락 여부 확인 |
| 한글이 깨진 고객명 수 | 1,136개 | 대부분 복구 | 원본 대조 진행 |
| 잘못 저장된 파일 수 | 3개 | 3개 재검증 | 백업 파일과 비교 |
| 수작업 수정 데이터 | 없음 | 112건 | 자동 복구 불가 항목 |
| 최종 복구 성공률 | – | 99.4% | 검증 기준 통과 |
수작업 수정이 필요한 데이터도 있었다
자동 복구 후에도 112건은 수작업으로 수정했다. 이 데이터들은 단순히 인코딩을 다시 지정하는 것만으로는 원래 이름을 확정하기 어려웠다.
예를 들어 고객명이 깨진 상태로 저장된 뒤 다시 열리고, 다시 저장된 흔적이 있는 행들이 있었다. 이런 경우에는 고객번호, 주문번호, 기존 CRM 데이터와 대조했다.
수작업 수정은 시간이 오래 걸렸지만, 무리하게 자동 변환하는 것보다 안전했다. 고객명은 단순 표시값이 아니라 실제 연락, 정산, CS 기록과 연결되는 값이기 때문이다.
다시 같은 실수를 막기 위해 만든 CSV 점검 기준
파일을 열기 전에 먼저 확인하는 8가지
복구가 끝난 뒤 바로 체크리스트를 만들었다. 다시는 CSV 파일을 습관적으로 더블클릭하지 않기 위해서였다.
체크리스트는 총 8개 항목으로 만들었고, 이후 같은 유형 오류 발생은 0건이었다. 실무에서는 거창한 시스템보다 이런 작은 기준이 더 큰 사고를 막아준다고 느꼈다.
| 번호 | CSV 파일 열기 전 체크리스트 | 확인 이유 |
|---|---|---|
| 1 | 원본 파일을 먼저 복사해 백업한다 | 잘못 저장해도 되돌릴 수 있게 하기 위해 |
| 2 | CSV를 엑셀에서 더블클릭으로 열지 않는다 | 자동 인코딩 해석 오류 방지 |
| 3 | VS Code 또는 Notepad++로 인코딩을 먼저 확인한다 | UTF-8, EUC-KR 여부 확인 |
| 4 | Excel에서는 데이터 가져오기로 연다 | 파일 원본 인코딩을 직접 선택하기 위해 |
| 5 | 미리보기에서 고객명 10개 이상을 확인한다 | 일부 행만 깨지는 경우 확인 |
| 6 | 행 수가 원본과 동일한지 비교한다 | 누락 또는 잘림 방지 |
| 7 | 저장 전 UTF-8-SIG 필요 여부를 확인한다 | 엑셀 호환성 확보 |
| 8 | 저장 후 다시 열어 한글 표시를 재확인한다 | 최종 검증 |
엑셀 더블클릭을 금지한 이유
엑셀 더블클릭이 항상 문제를 만드는 것은 아니다. 하지만 고객명처럼 한글 데이터가 들어 있고, 파일 출처가 여러 시스템에 걸쳐 있다면 위험한 습관이 될 수 있다.
내가 겪은 문제는 복잡한 해킹이나 서버 장애가 아니었다. 그냥 CSV 파일을 더블클릭해서 열었고, 인코딩을 잘못 해석한 상태에서 일부 파일을 저장했을 뿐이다.
그 작은 행동 때문에 2일 동안 7개 파일과 18,420행을 다시 확인해야 했다. 그래서 지금은 CSV 파일을 받으면 먼저 백업하고, 인코딩부터 확인한다.
마무리하며, CSV는 단순한 엑셀 파일이 아니었다
이번 일을 겪기 전까지 나는 CSV를 엑셀의 가벼운 버전 정도로 생각했다. 하지만 실제로는 인코딩, 구분자, 저장 방식에 따라 전혀 다른 결과가 나올 수 있는 텍스트 데이터였다.
특히 고객명처럼 한글이 포함된 데이터는 열기 전 확인이 중요하다. 화면에 깨져 보이는 것과 실제 데이터가 손상된 것은 다르지만, 깨진 상태로 저장하는 순간 복구 난이도는 크게 올라간다.
2026년 1월 14일 오전 10시 20분에 시작된 이 문제는 2026년 1월 15일 오후 5시 40분에야 정리됐다. 최종 복구 성공률은 99.4%였고, 수작업으로 수정한 데이터는 112건이었다.
전문가처럼 완벽하게 처리했다고 말하기는 어렵다. 다만 이 일을 겪고 난 뒤, CSV 파일을 대하는 방식은 완전히 바뀌었다.
FAQ
Q1. CSV 한글이 깨지면 파일이 손상된 건가요?
항상 손상된 것은 아닙니다. UTF-8 파일을 엑셀이 EUC-KR처럼 해석하면 데이터는 살아 있어도 화면에서는 한글이 깨져 보일 수 있습니다.
다만 깨진 상태로 다시 저장하면 실제로 복구가 어려워질 수 있으므로, 먼저 원본을 백업하고 인코딩을 확인하는 것이 안전합니다.
Q2. 엑셀에서 CSV를 열 때 가장 안전한 방법은 무엇인가요?
더블클릭으로 바로 열기보다 Excel 2021의 데이터 가져오기 기능을 사용하는 것이 안전했습니다. 이 방식은 UTF-8 같은 파일 원본 인코딩을 직접 지정할 수 있습니다.
미리보기에서 고객명, 주소, 메모처럼 한글이 들어간 열을 먼저 확인한 뒤 불러오는 습관이 필요합니다.
Q3. UTF-8과 UTF-8-BOM은 왜 구분해야 하나요?
UTF-8은 표준적으로 많이 쓰이는 인코딩이지만, 일부 엑셀 환경에서는 BOM이 없는 UTF-8 CSV를 자동으로 제대로 인식하지 못할 수 있습니다.
그래서 엑셀에서 자주 열어야 하는 CSV라면 UTF-8-SIG 또는 UTF-8-BOM 형태로 저장하는 것이 한글 깨짐을 줄이는 데 도움이 됐습니다.